 모닥위키
모닥위키데이터베이스란 무엇인가?
데이터베이스에 대하여 정리한 글입니다.
데이터베이스
전자적으로 저장되는 체계적인 데이터 모음을 말한다. 단어, 숫자, 이미지, 비디오 등 디지털로 표현가능한 모든 유형이 대상이 될 수 있다. DataBase Management System(DBMS)을 사용하면 데이터를 쉽게 접근·제어할 수 있다.
관계형 DB
키와 값이라는 아주 간단한 관계를 목록으로 만들어 전산 시스템에서 활용할 수 있도록 만든 데이터의 집합이다. Relational Database(RDB)는 관계형이라는 이름처럼 서로 다른 데이터 집합 간의 관계를 설정할 수 있다는 것이 큰 특징이다. 또한, 정확하고 명시적인 데이터 목록 명세가 미리 등록되어 있어야 한다는 특징도 있다.
Table
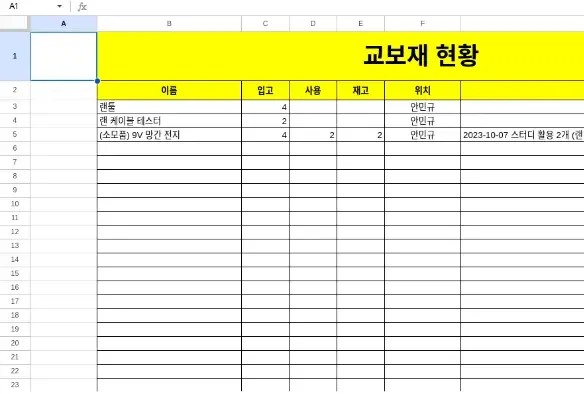
테이블
데이터를 관리하기 위해서 가장 기본이 되는 개념으로는 테이블이라는 개념을 알아야 한다. 엑셀을 떠올리면 쉽게 이해할 수 있는데 행과 열로 이루어져 좌표 번호를 알면 셀을 찾을 수 있고 해당하는 곳의 데이터를 찾을 수 있게 되어있다.
Tuple
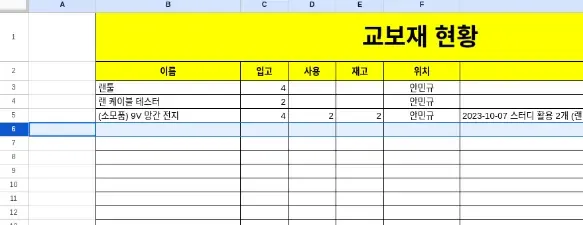
튜플
튜플은 영문권에서 사용하는 단어인 것 같은데 번역된 것을 보면 한국어인데도 도무지 읽히지가 않는다. 쉽게 엑셀에서 행에 해당하는 것이 튜플이라고 생각하면 된다. 그래서인지 실무에서도 로우(row)나 컬럼(column)으로 이야기하지 튜플이나 어트리뷰트라고 대화하지는 않는다.
Attribute
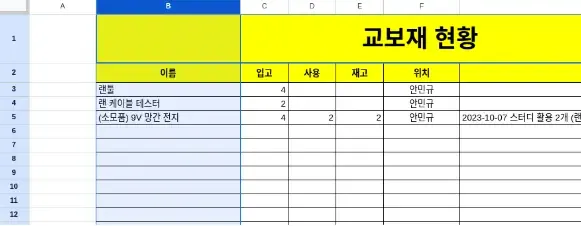
속성
튜플과 같은 이유로 컬럼(column)이라고 더 많이 불린다. 정해진 이름이 있고 해당하는 데이터들이 행별로 위치한다.
NoSQL DB
NoSQL은 실무에서 비관계형, 또는 덜 제약적인 데이터베이스를 일컫는다. 카를로 스트로찌(Carlo Strozzi)가 '표준 SQL을 사용하지 않은' 자신의 경량 관계형 데이터베이스를 가리켜 NoSQL이라는 단어를 사용했다. 지금 우리가 인지하는 NoSQL과는 거리가 좀 있는데 현재 사용되는 NoSQL이라는 단어는 개념상 NoREL이 더 적합하다는 의견을 이야기 했다고도 한다.1
전통적인 SQL 문법 뿐만 아니라 다른 방식의 엑세스(Restful API 등)를 가능하게 하는 것으로 'Not Only SQL' 이라는 뜻으로 이해하기도 한다. 이 해석이 카를로찌가 처음 의도했던 바와 가장 가깝다. 그러나, 흔히 실무에서 이야기하는 NoSQL은 '비관계형, 또는 덜 제약적인 데이터베이스'를 말한다.
아무래도 RDB가 대세였던 국내상황에서 Elasticsearch나 Firebase같은 제품들이 급속도로 알려지기 시작하며 준비하지 못 한채로 실무와 영업에 반영되며 다른 의미로 퍼져버렸기 때문이라 생각한다. 해당 개념들이 실제로는 20년도 훌쩍 넘은 것들이란걸 감안하면 준비를 '안' 했다고 말하는게 맞겠다.
실제로 관계형 DB에 익숙했던 사람들이 처음 접할 때에는 20년도 넘은 구식의 테이블 정의서나 구현방식, SQL을 사용하지 않는 점도 그렇고 마치 대척점에 있는 기분이 들었을 것이다.
DBMS
데이터베이스 관리 시스템(DataBase Management System)으로 데이터를 저장·검색·편집할 수 있는 다양한 기능을 제공하는 소프트웨어를 칭한다. DBMS는 프로그램이 실행될 때 매우 자주 사용되기 때문에 많은 사람들이 쉽게 접하고 사용한다. 상투적인 설명보다는 개인적인 궁금증에 대한 부분들을 위주로 학습한 것들을 정리해보겠다.
그냥 파일을 사용하면 안되나?
써도 된다. 단순히 새 줄과 콤마로 구분되는 CSV 형식이나 JSON 형식으로 저장하며 데이터를 관리해도 무방하다. 허나 파일이 커지거나 너무 많은 파일이 생겨도 파일 시스템으로는 해결할 수 없는 문제점들이 발생하기 시작한다.
그리고 데이터를 접근하고 제어하는 부분에서 DBMS는 다양한 기능과 편의를 제공한다. 저장, 관리, 검색, 집계, 일괄 처리같은 기능을 파일 시스템을 읽고 쓰며 직접 구현하는 것 보다 이미 잘 되어있는 DBMS를 하나 선정하여 활용하면 더 빠르고 안정성 있는 서비스를 구현할 수 있다. 공동작업자들이 새로운 것을 학습하는 시간을 줄이고 일관성있는 코드를 생산할 수 있는 것도 생산성에 큰 요소로 작용하기 때문에 많은 시스템들이 DBMS를 도입하여 활용하는 것이다.
또한, 데이터를 관리함에 있어서 성능과 관련된 많은 알고리즘들이 기본적으로 제공되므로 본인이 데이터베이스에 한 획을 그을 야망이 있는 것이 아니라면 그냥 설치해서 쓰는 것을 추천한다.
데이터와 파일은 다른 것인가?
DB로 작업을 하다보니 의문이 하나 생겼었다. 도대체 이 데이터란 놈이 어떻게 저장되는가? 내가 알고 있는 파일과는 다른건가? 바이너리인가? 바이너리도 파일인데 그럼 도대체 데이터는 어떤 것인가? 하는 이상한 궁금증이다.
결론부터 말하자면 그냥 파일이다. 알고리즘이 적용된 파일이라고 생각하면 좀 더 쉽게 상상해볼 수 있다. DBMS도 결국 프로그램 중 하나일 뿐이다.
Postgresql의 경우
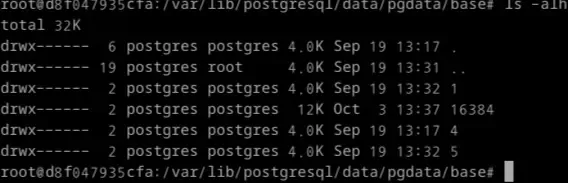
Postgresql 1
상상이 안된다면 직접 까보도록 하자. 대표적으로 Postgresql이 사용하는 데이터이다. Postgresql이 이런식으로 데이터를 저장한다고 한다. 디렉토리를 구분짓거나 파일명을 결정짓는 방법들도 검색하면 나오는데 궁금하면 찾아보자. 검색에 효율적인 방식으로 저장할 것이다.
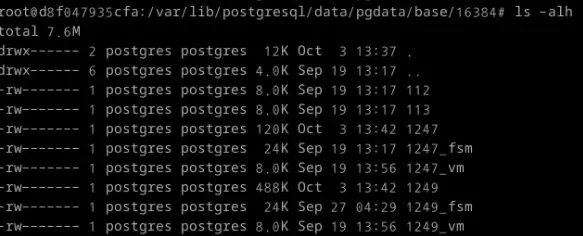
Postgresql 2

Postgresql 3
안쪽에 데이터를 찾아서 직접 cat을 통해 확인해보면 바이너리 파일임을 확인할 수 있다. 우리가 저장하는 파일들을 효율적인 알고리즘을 통해 데이터를 인코딩하여 저장한다.
Opensearch의 경우
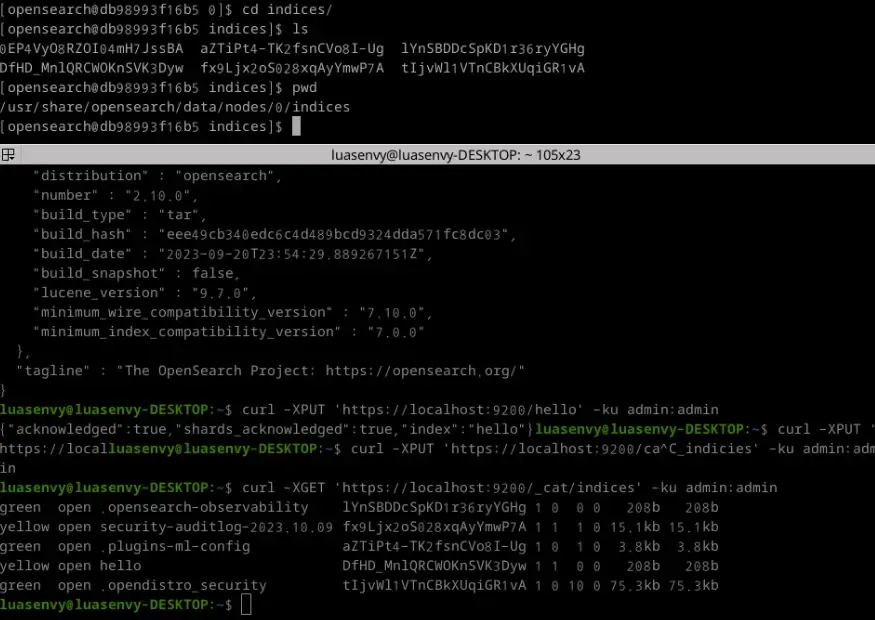
Opensearch 1
이번엔 Opensearch를 까보자. 위는 Docker를 통해 컨테이너에서 테스트한 내용이다. 인덱스별로 ID를 따서 내부 디렉토리 구조를 관리를 하고 있는 걸 볼 수 있다. 'hello'의 인덱스 ID를 통해 디렉토리를 접근해보면 또 여러가지 파일들이 존재한다.
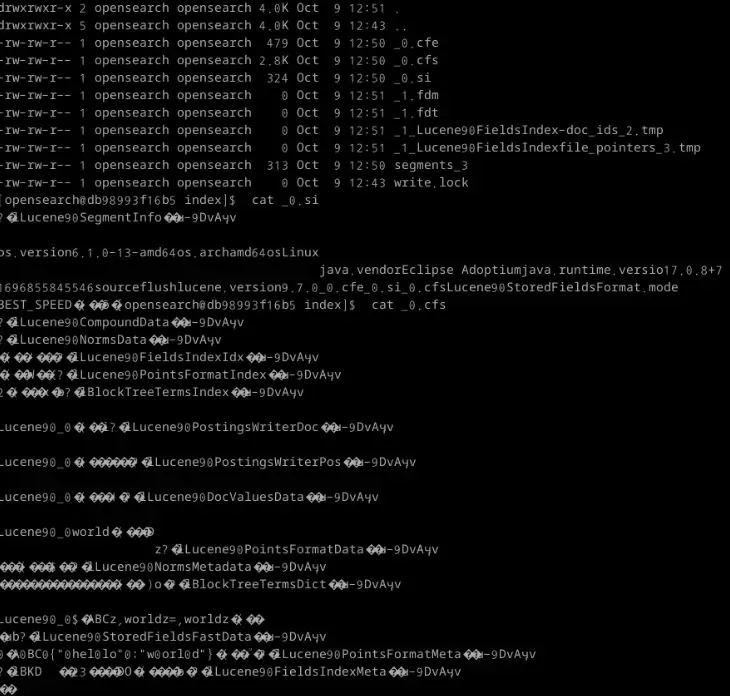
Opensearch 2
로컬 테스트로 데이터를 하나 밀어넣고 디렉토리를 뒤져보니 translog가 증가하면서 state안에 여러 파일들이 또 생기고 관리되는걸 볼 수 있었다. cat을 통해 직접 확인해보면 마찬가지로 인코딩된 데이터들이 저장되어있다. Lucene 엔진 이름도 보이고 중간중간에 밀어넣은 테스트 데이터도 확인할 수 있다. Postgresql과 마찬가지로 Opensearch도 구현된 알고리즘을 통해 파일이 관리되고 있음을 확인할 수 있었다.
색인이란?
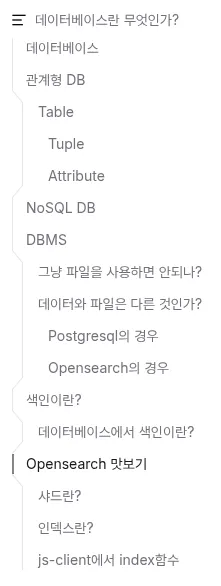
목차
사전적 의미는 책 속의 낱말이나 구절 또는 관련된 지시자를 찾아보기 쉽도록 일정한 순서로 나열한 목록을 말한다. 위 사진처럼 어디에 뭐가 있는지 간략하게 정리해둔 것을 목차 또는 색인이라고 한다. 색인을 참고하면 원하는 데이터가 몇 페이지에 있는지 하나하나 찾을 필요 없이 해당 페이지로 바로 건너뛰어 원하는 데이터를 정확하게 찾을 수 있다.
데이터베이스에서 색인이란?
데이터베이스에서 말하는 색인, 인덱스, 인덱싱도 크게 다른걸 말하는 것은 아니다. 색인한다 라고도 표현하지만 인덱싱 한다라고 표현하기도 한다. 튜플(row)에 대해 추가적인 저장공간을 활용하여 검색 속도를 향상시키기 위한 자료구조를 일컫는다.
말이 어려울 수 있는데 조금 더 쉽게 이야기하면 하나의 행을 저장하고 '책갈피를 달아둔다'는 이야기다. 결국 목차처럼 색인을 만들어 두는 것과 일맥상통한다. DBMS는 이 책갈피를 통해 사용자가 데이터를 찾을 때 좀 더 빨리 찾을 수 있다. 책갈피를 달고 확인하는 것도 여러가지 방법론이 존재하는데 비트맵 인덱스, 조밀 인덱스, 희소 인덱스, 역방향 인덱스와 같은 종류들이 있다고 한다.
데이터베이스가 저장하는 데이터의 유형이나 검색하는 방식은 점점 더 많은 데이터가 대상이 될 수록 시간이 더 걸린다는 숙명이 있다. 색인이 되어있지 않다면 데이터베이스는 처음부터 끝까지 찾아야 할 것이며 자료의 위치에 따라 성능이 좌우되는 현상을 보이게 된다. 그렇기 때문에 일반적으로 데이터베이스는 색인을 통하여 쿼리의 성능을 높인다.
데이터를 저장할 때 순서화하고 어디에 저장되어 있는지 일종의 북마크를 찍어두어 다음에 쿼리를 실행할 때 데이터베이스는 이 색인을 참조하여 불필요한 검색 구간을 건너뛰고 데이터가 어디쯤 있는지 선별하여 빠르고 정확하게 원하는 자료를 찾을 수 있다. 이런 색인은 검색뿐만 아니라 갱신과 삭제 성능도 함께 향상시키는데 갱신과 삭제를 위해서는 반드시 튜플을 먼저 검색해야 하기 때문이다.
Opensearch 맛보기
샤드란?
샤드는 Lucene의 인덱스 인스턴스이다. 데이터 집합에 대한 쿼리를 색인하고 처리하는 검색 엔진이라고 생각할 수 있다.
인덱스란?
[
{
"_index": "my-index",
"_source": {
"name": "hello",
"say": "world",
"props": {
"hello": "world"
}
}
},
// ...
]
Opensearch에서 '인덱스'란 앞서 설명한 자료구조를 말하지 않는다. 문서를 모아둘 수 있는 논리적 구분을 뜻한다. 테이블의 개념과 대응된다. 하나의 문서는 중첩된 튜플 형태로 표현할 수 있다. 쉽게 JSONObject를 떠올리면 된다.
js-client에서 index함수
패키지가 제공하는 index(), create() 두가지 모두 문서를 만드는 함수이다. 차이는 각각 동일한 ID의 문서가 있을 때 확인할 수 있는데 index함수는 데이터를 덮어 씌우고 create함수는 갱신하지 않는다.
Footnotes
-
위키백과 기여자, "NoSQL," 위키백과, https://ko.wikipedia.org/w/index.php?title=NoSQL&oldid=39309010 (2025년 9월 22일에 접근). ↩
초판: 2024. 08. 25. 21:40:17
© 2024 이 문서는 "CC BY 4.0 국제규약" 라이선스로 배포 되었습니다. 모든 권리는 저자에게 있습니다.