 모닥위키
모닥위키자료구조
자료구조는 컴퓨터 산업 전반에 걸쳐 사용되는 데이터의 저장·정렬·검색 기법 등을 일컫는다. 리스트, 선형 리스트, 비선형 리스트, 맵, 해시 테이블, 큐, 스택, 트리, 이진트리, 트라이 등등 데이터에 맞게, 상황에 맞게, 목적에 맞게 더 효율적인 데이터 구조를 선택해야 좋은 프로그램이 될 수 있다.
단순히 자료구조가 어떤식으로 구성되고 작동하는지를 이해했다면 해당 자료구조를 어떻게 해야 원하는 데이터를 더 빠르게 검색할 수 있는지, 어떤 알고리즘으로 정렬을 해야 더 효율적으로 처리할 수 있는지 등도 자료구조에서 다루어야할 큰 챕터중에 하나이다. 너무도 많은 종류와 방법들이 있기 때문에 모두 다루지는 않을 것이고 웹 프로그래밍을 할 때에 가장 많이 마주치고 느낄 수 있는 몇몇 가지만 소개하려고 한다. 만약, 여기서 소개하는 것 외에도 관심이 있는 사람이라면 Data Structures in JavaScript에서 더 깊게 학습해 보는 것을 추천한다.
스택과 큐
콜 스택과 메시지 큐와 이벤트 루프에서 스택과 큐를 이미 다루었었다. 간단하게 표현이 가능하기에 해당 글을 참고하시길 바란다.
트리
| 트리 | 조직도 |
|---|---|
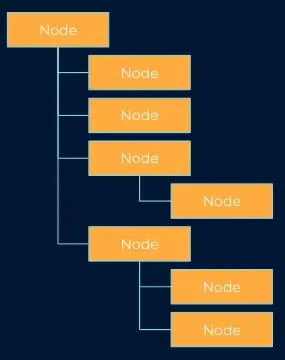 트리 | 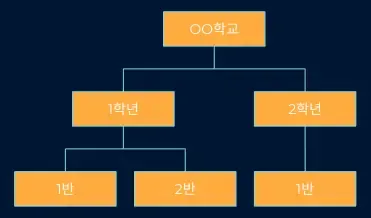 조직도 |
트리는 디렉토리 구조를 떠올리면 이해하기 쉽다. 각 항목은 노드라고 불리우며 이 노드는 각자 하위로 여러 개의 노드를 가질 수 있는 자료구조이다. 디렉토리 구조가 생소하면 조직도를 떠올려보면 된다. 방향만 다르게 그렸지 동일한 자료구조이다.
// 직렬화 표현
[
{ "id": 1, "parentId": null },
{ "id": 2, "parentId": 1 },
{ "id": 3, "parentId": 1 },
{ "id": 4, "parentId": 3 },
{ "id": 5, "parentId": 3 },
{ "id": 6, "parentId": 3 },
{ "id": 7, "parentId": 3 }
]
// 중첩 표현
[
{
"id": 1,
"children": [
{ "id": 2 },
{
"id": 3,
"children": [
{ "id": 4 },
{ "id": 5 },
{ "id": 6 },
{ "id": 7 }
]
}
]
}
]
자바 스크립트에서 흔히 트리 데이터를 저장할 때에는 두가지 방식을 사용한다. 상위 노드의 ID를 하위 노드가 가지고 있는 형태의 직렬화된 형태 또는 특정 필드에 자식노드 그 자체를 할당하는 중첩된 형태이다.
두 가지 모두 장단이 있는데 직렬화 데이터는 배열이므로 filter(), map(), find() 와 같은 내장함수를 활용할 수 있어서 데이터 조작이 편리하고 성능이 좋다. 하지만 트리를 구성할 때 상위 ID를 검색해 상위 노드를 찾아야하고 전체 트리 구성이 어떻게 되어있는지 알아채기가 쉽지 않다.
중첩 데이터로 구성된 데이터는 반대로 전체 트리 구조를 한 눈에 알아볼 수 있지만 검색이 쉽지 않다는 단점이 있다. 노드를 순회하기 위해 재귀함수를 사용해야해서 코드가 복잡해지고 데이터가 거대해질 수록 성능이 떨어진다. 상위 노드를 찾기 위해 특정 필드에 부모 노드의 메모리 주소값을 저장하는 경우도 있다.
초판: 2024. 08. 20. 17:11:59
© 2024 이 문서는 "CC BY 4.0 국제규약" 라이선스로 배포 되었습니다. 모든 권리는 저자에게 있습니다.